In recent years, given that the Unicode Standard has been updated, the number of Chinese character (Hanzi/Kanji) codes available for text databases of historical documents written in Chinese and Japanese has increased significantly. With the addition of the CJK Unified Ideographs Extension G in 2020, the current Unicode Standard now contains a total of more than 93,000 Chinese characters (Lunde, 2021). To maximize reproduction of the content in historical documents, it is desirable to use Chinese characters that can be displayed in a form that is as close to the original glyphs as possible.
TEI-encoded 1 text databases are also becoming increasingly common. However, there are still few examples of the use of these extended Chinese characters in publicly available text databases. Possible causes are the difficulty of checking whether a character can be represented in Unicode and determining how to input those newly included characters in Unicode without input method support.
The most common computer-based Chinese character input method entails reading the character. If the reading is inconclusive or if the character has not yet been incorporated into an input method, Ideographic Description Sequence (IDS) can be used to search for the input (The Unicode Consortium, 2021).
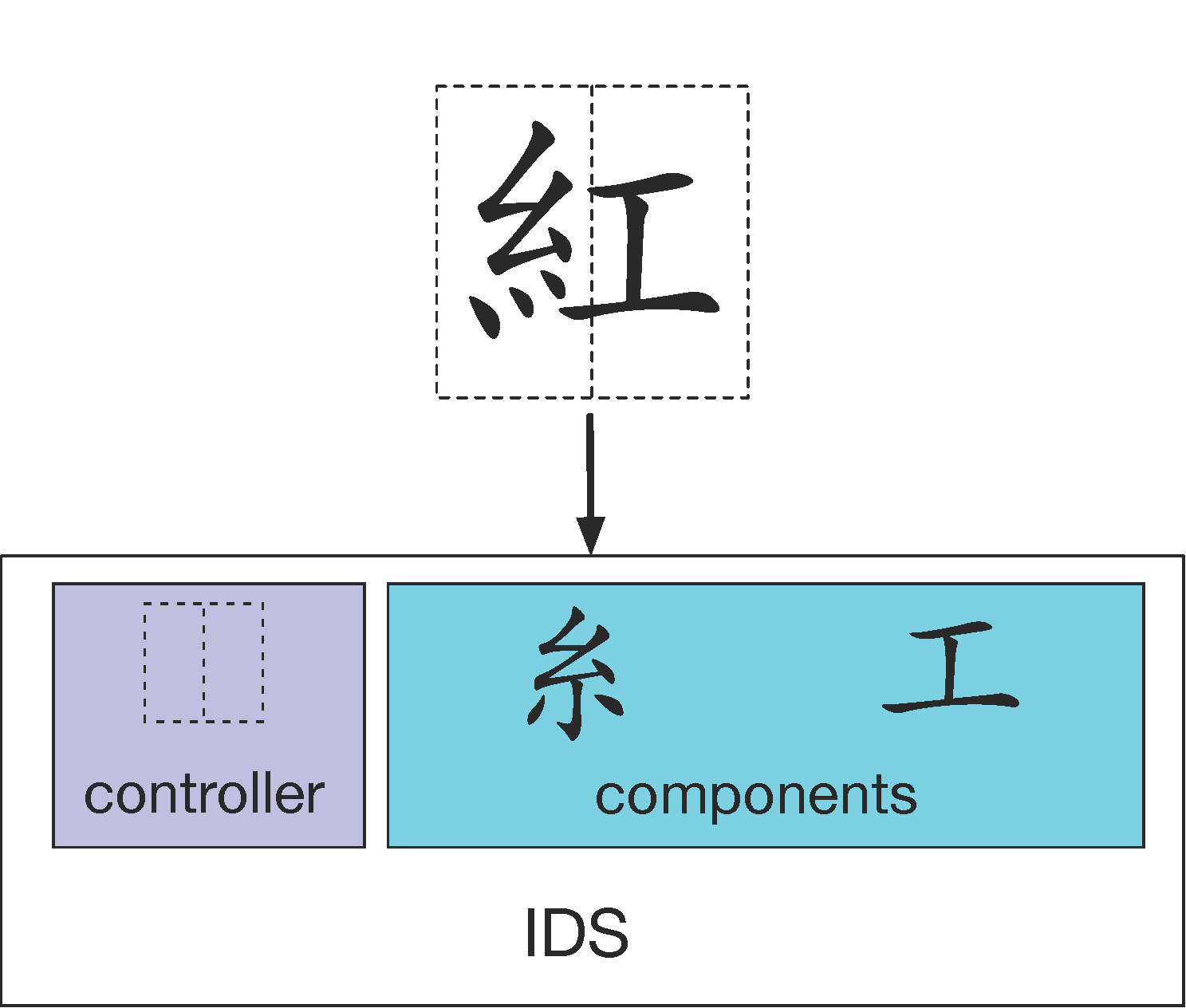
IDS describes Chinese characters according to their mechanism and components. For example, 紅(red) can be described as ⿰ 糸工 (Figure 1). Tools such as CHISE 2 (Morioka, 2008) and GlyphWiki 3 (上地, 2018) are useful to search for Chinese characters (in Japanese), but no existing tools specialize in inputting Chinese characters and allow TEI-encoded output data in a format suitable for reprinting. Regarding actual reprinting, there are three issues that need to be addressed.
Figure 1: a sample of IDS
To solve the above issues, we have developed a tool for searching and inputting Chinese characters that cannot be input via ordinary input methods using Chinese character components and stroke numbers. The tool has the following features, and the corresponding issue is given in parentheses:
The tool uses IDS data from CHISE and glyph images from GlyphWiki. Compared to both, users can search and input Chinese characters more efficiently by filtering according to the number of strokes remaining (Figure 2). Furthermore, it is easy to select and copy the result in one click, offering a fast response. It is also possible to copy the Chinese characters you want to input as a block of TEI-encoded XML to create a text database. This saves database creators’ time. Here is an example (Figure 4).
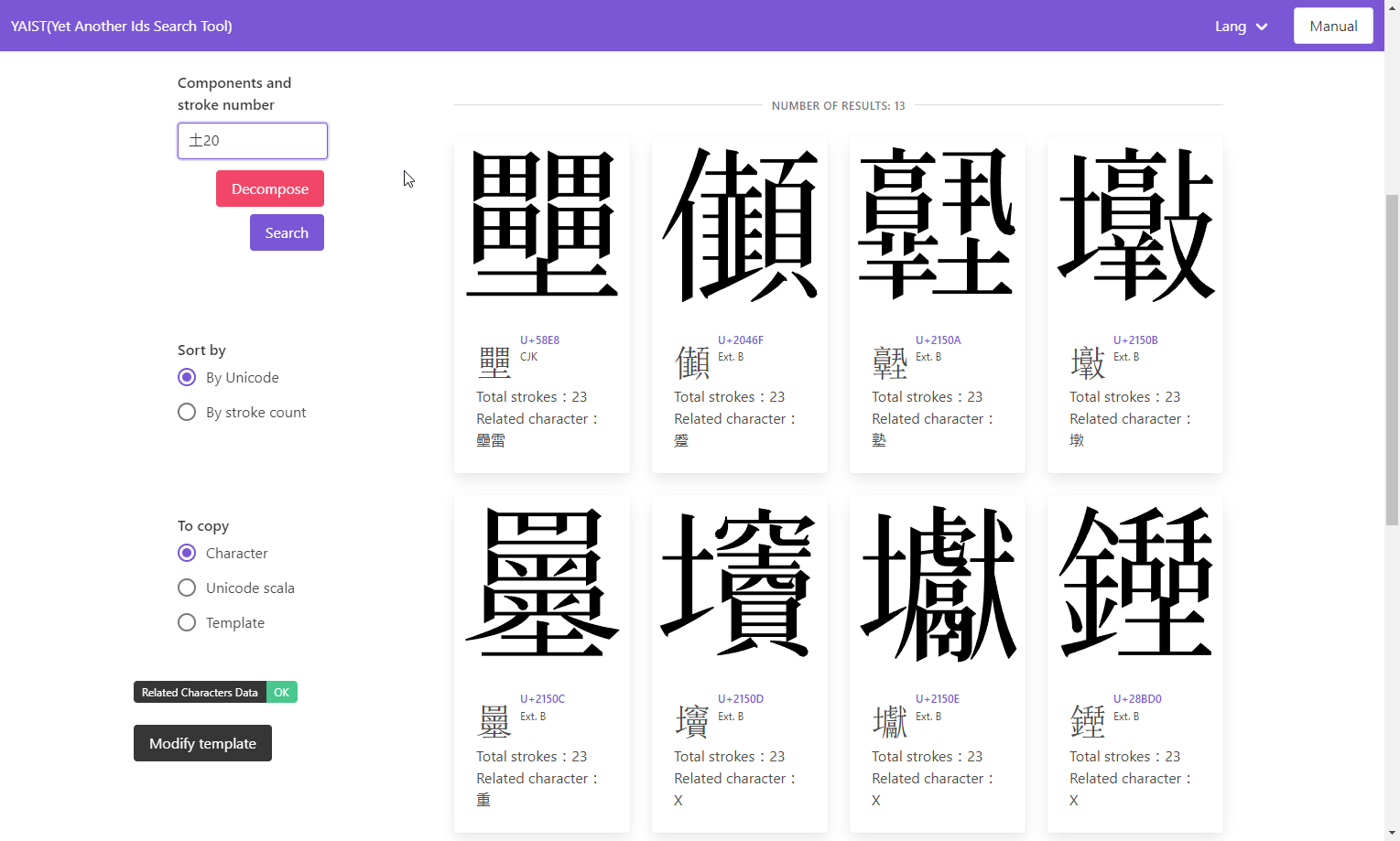
Figure 2: interface of the tool
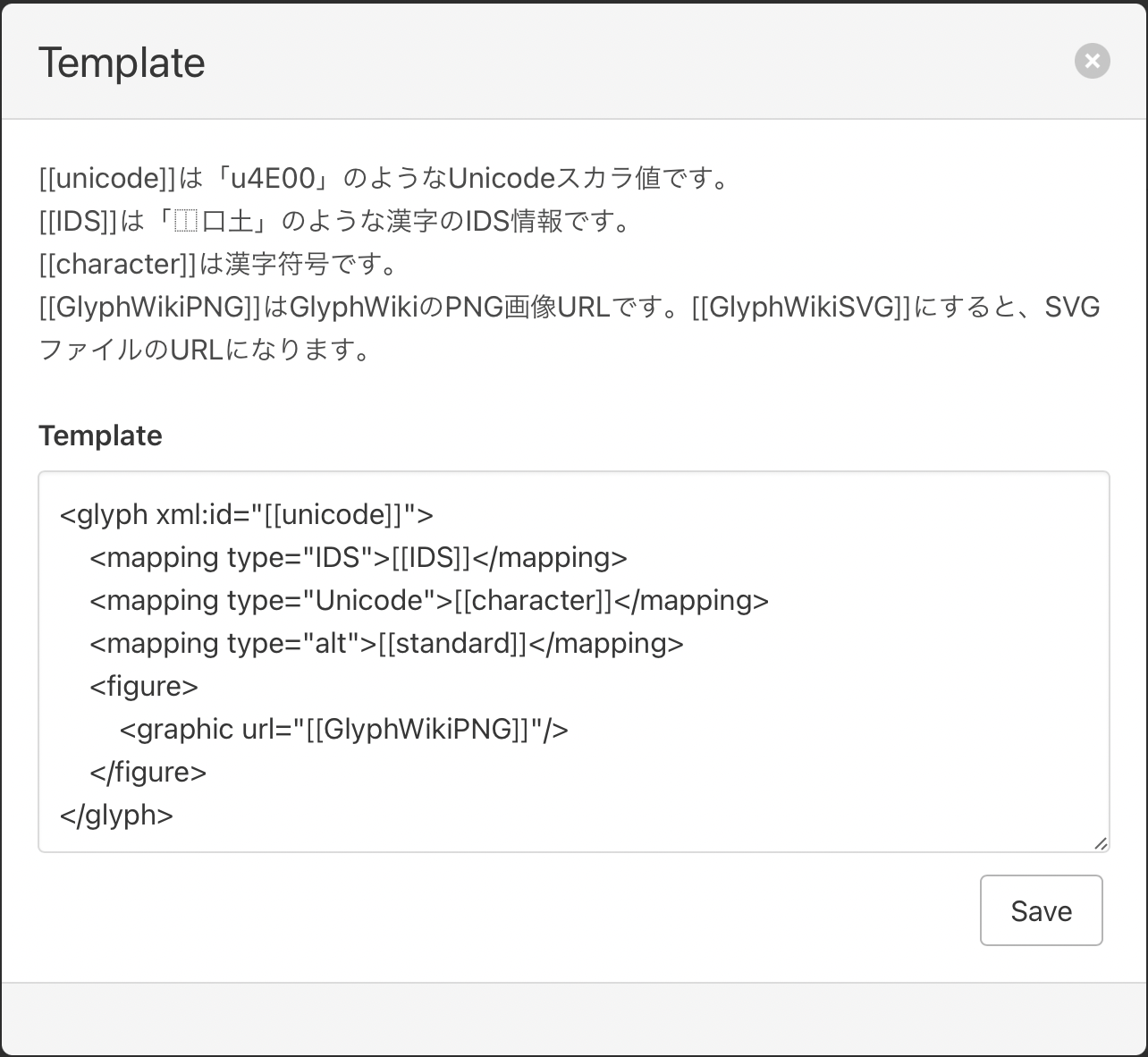
Figure 3: customizable XML block template

Figure 4: TEI-encoded sample
This tool has been applied to the creation of TEI-encoded text databases at the Historiographical Institute, University of Tokyo 6 . Details will be presented in the poster.
https://tei-c.org/
https://www.chise.org/
https://www.glyphwiki.org/
https://gitlab.chise.org/CHISE/ids
https://www.unicode.org/Public/UCD/latest/ucd/Unihan.zip
https://www.hi.u-tokyo.ac.jp/en/