In recent years, the digitisation of newspapers has made a lot of progress, and large national and international initiatives like Trove 1 , Chronicling America 2 , Europeana Newspapers 3 , Impresso 4 , NewsEye 5 , Oceanic Exchanges 6 , OCR-D 7 , Deutsches Zeitungsportal 8 , and L iving with Machines 9 emerged that are building up on and going beyond sheer digitisation, venturing into various areas of content analysis ( Oberbichler et al, 2021 ) . Also, the outcomes of these initiatives are usually provided online with open access, and publications increasingly follow the FAIR principles ( Wilkinson et al, 2016 ) . However, most of the textual content covered is printed in Latin script languages, and to a large degree the analytical systems rely on linguistic features like word boundaries, digital lexica, or tagged corpora.
Responding to this from an Asian perspective, i.e. looking at materials from regions where non-Latin scripts prevail, the situation is different. In our case we are working with newspapers from Republican China. Although there are some projects working on historical Chinese newspapers ( Stewart et al, 2020 ) , results have so far rarely been published. Other initiatives provide their final results as commercial products. In general, a certain reluctance can be observed when it comes to publishing research methodologies, not to mention the open access sharing of ground truth, test corpora, or trained models ( Arnold et al, forthcoming ) .
In our project we collected periodicals from the Republican era as image scans ( Sung et al, 2014 ) and started OCR experiments to transform them into machine readable full text.

Fig. 1: One of the 9385 fold scans of Jing bao
Looking closer at Jing bao 晶報 (The Crystal) (cf. Fig. 1), an entertainment newspaper that ran from 1919 to 1940, we soon learned that the key issue of OCR’ing the material actually lies in the page-level segmentation. We therefore started creating ground truth (GT) for geometrical data featuring semantically grouped bounding boxes with labels (article, image, advertisement, marginalia). We then used the resulting dataset to train dhSegment and have the network detect content areas on the folds ( Arnold, forthcoming ) (Fig. 2).

Fig. 2: Automatic page segmentation results. Blocks with text content are shown in yellow.
Additionally, we created a text GT that not only covers all text in a machine readable local XML format, but also contains information about reading sequence running direction of the text. Based on this GT we were able to process a first set of manual crops, introducing a character segmentation method for grid-based printing layouts which produces over 90,000 labeled images of single characters ( Henke, 2021 ) . In this work, a GoogLeNet is trained as an OCR classifier on said character images after extensive pre-training on synthetical character image data created from font files. Additional error correction using language models yields an accuracy of 97.44%.
In our presentation we introduce our work on developing a document image processing pipeline currently focusing on Republican Chinese newspapers with complex layouts like the Jing bao . We will present the following concrete contributions:
- A page-level segmentation approach (as seen in Fig. 2) yielding single text blocks.
- An OCR pipeline taking single text blocks as input.
While Arnold (forthcoming) presented first promising experiments regarding (1), in this presentation we will concentrate on (2). Our evaluation metric for OCR output is the character error rate (CER) with regard to the ground truth annotation of every text block crop, which, based on the Levenshtein distance, is computed by:
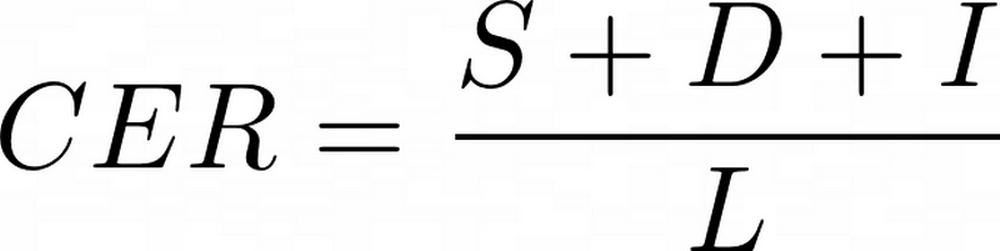
( S , D , I = number of substitutions, deletions, insertions; L = length of the reference sequence, i.e. corresponding GT text).
The character segmentation approach presented in Henke ( 2021 ) can however only process text blocks where characters are printed in a grid-like layout, which accounts for a very small portion of the Jing bao . Hence, there is a particular need for efficient character detection in less stable layout situations within text blocks, before passing single character images on to the actual OCR engine. As a baseline, we leverage the publicly available state-of-the-art OCR tool Tesseract ( Smith, 2007 ) which provides out-of-the-box segmentation+recognition models even for vertically printed traditional Chinese. Tesseract however seems to struggle with the low input image resolution (~ 25x25 px per character) and overall inconsistent scan quality, leading to a very high CER of 47.85% on the test set from Henke ( 2021 ).
To solve this issue, we use the readily-trained HRCenterNet from T ang et al. ( 2020 ) for character detection, and crop the bounding boxes to feed them into the GoogLeNet trained in Henke ( 2021 ). However, while our crops have a great variety of aspect ratios, the HRCenterNet expects at least nearly-squared rectangles. Hence, we cut the original images into 250x250 px tiles with a 50 px overlap (both horizontally and vertically, Fig. 3c). Bounding boxes (Fig. 3d) found in the overlapping sections are filtered during the non-maximum suppression (NMS) operation already included in the HRCenterNet pipeline (Fig. 3e).
| a |

|
| b |

|
| c |

|
| d |

|
| e |

|
Fig 3: a) original image, b) image after contrast enhancing, c) tiling with overlap, d) bounding boxes found by HRCenterNet before NMS, e) final result after reconnection of tiles and NMS
In addition, Fig. 4 shows how the HRCenterNet largely profits from contrast-enhancement (Fig 3b) during image pre-processing, especially for low-contrast input images.

|

|
Fig 4: Effects of contrast enhancement on character detection using HRCenterNet
Using the above method, the CER on the test set of Henke ( 2021 ) is reduced to 1 0.51 % .
In the presentation we will show how the results can be confirmed on a non-grid-based section of the corpus, for which we currently create GT annotations. We are confident that the additional pre-processing of crops and individual character images will help to further reduce the CER, and in combination with (1), yield a powerful document-level OCR pipeline for the Jing bao and similar Republican newspapers. This will not only open the door to further processing with the tools of Digital Humanities, but also further contribute to FAIR-based work in the diverse Asian sphere.